
High Availability, Redesigned From The Ground Up
What the new HA engine means for your Syncplify Server! deployments

High Availability is one of the hardest problems in distributed systems engineering. Not because the individual mechanisms are exotic, but because the interactions between them, under the full range of real-world conditions, are subtle in ways that only reveal themselves over time. Clock drift that only appears during a DST transition. A network partition that heals in the middle of a pull cycle. A node that crashes between writing a change to the log and pushing it to peers.
The first generation of Syncplify Server!’s HA subsystem was built incrementally, as the product grew and as customer deployments grew more ambitious. It worked. But four years of production data, support cases, and internal tooling gave us a precise catalog of the edge cases it handled imperfectly and the operational experiences that were harder than they needed to be. Rather than continue grafting improvements onto a design which foundational assumptions were no longer sound, we made the decision to rewrite the entire HA subsystem from scratch.
This is not a reversal. It’s engineering maturity. Here’s what changes.
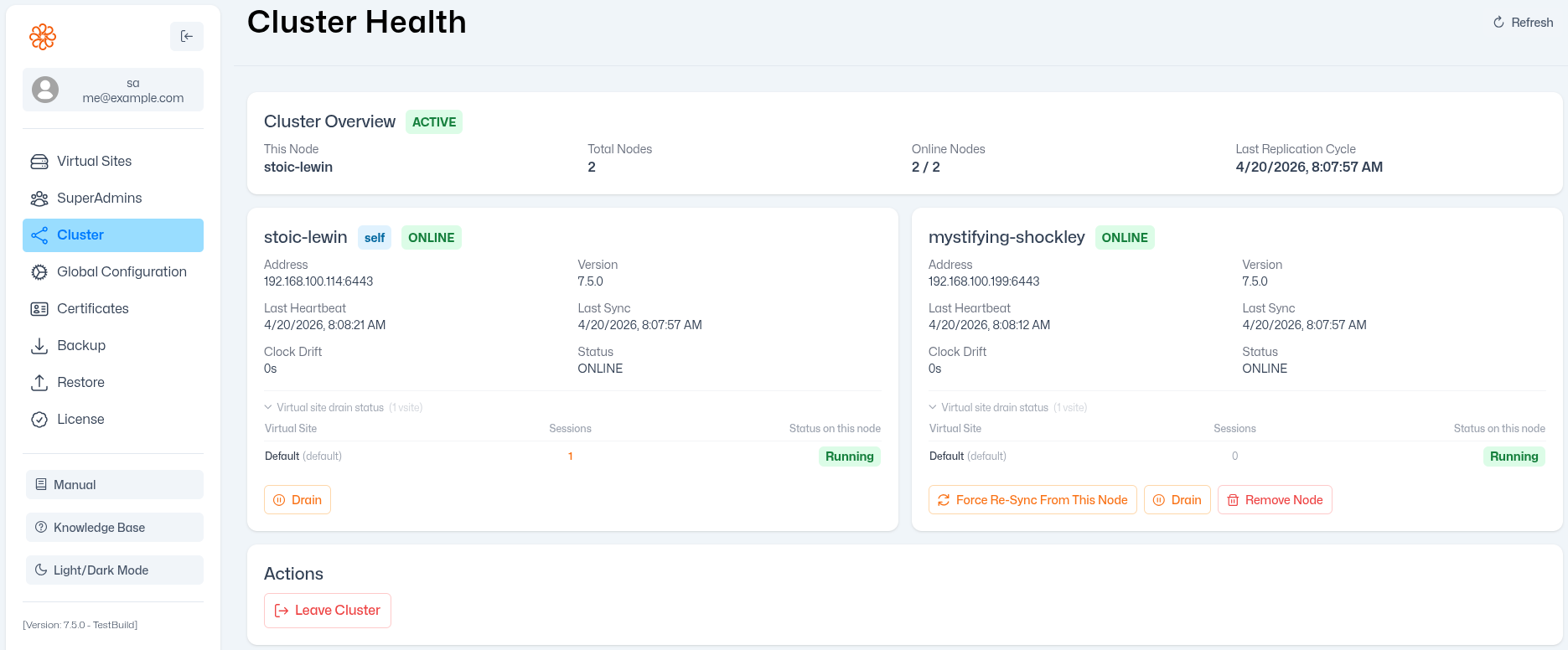
Automatic Recovery From Node Failures
When a node goes offline, the current implementation keeps it marked offline until the cluster is explicitly told to reset it. A transient hiccup, something that resolved itself in 30 seconds, can still require administrative intervention to clear.
The new engine recovers automatically. When an offline node comes back, the cluster detects it, catches it up on any missed changes, and resumes normal operation. No manual steps, no scheduled tasks to babysit.
For most customers on stable infrastructure, this will never matter. For customers running in cloud environments with occasional transient connectivity events, it matters every week.
A Dedicated Heartbeat, Separate From Data Sync
The existing subsystem infers node health from whether data synchronization succeeds. If a node has nothing new to sync, there is no communication at all, and silence is indistinguishable from unavailability.
The new engine introduces a lightweight, continuous heartbeat that runs independently of data replication. The cluster always has an accurate, current picture of which nodes are reachable, regardless of whether any data has changed recently.
Continuous Clock Verification
All timestamp-based HA implementations require synchronized clocks. The new engine goes further: it continuously verifies clock accuracy continuously during operation, not just at startup, and it can detect when a specific node is the one drifting, rather than only detecting that a difference exists. A node that determines it is the source of drift can self-quarantine from pushing changes, preventing incorrect data from propagating.
Stronger Inter-Node Authentication
Every inter-node request in the new design is cryptographically signed, covering the full request body. A timestamp embedded in every signature prevents replay attacks. Combined with TLS transport, this closes a class of inter-node threat scenarios that the previous implementation did not fully address.
A Wire Format That Survives Rolling Upgrades
The previous implementation used a binary encoding that fails silently when the data structures on two nodes diverge, as they inevitably do during an upgrade. The new design uses a versioned, human-readable wire format. Unknown fields are ignored gracefully. Protocol version mismatches are detected and reported cleanly rather than causing silent data corruption.
Automatic Tombstone Purging
Deletion records used to accumulate indefinitely, requiring manual cleanup. The new engine purges them automatically on a configurable schedule. A node that has been offline long enough to miss the purge window is handled gracefully on reconnection, with no operator involvement required.
The Worker Is Simpler
In the current design, the worker process participates in HA replication with its own sync cycle and its own database connections for that purpose. In the new design, replication is an exclusive responsibility of the ss-webrest process. The worker is notified of relevant changes via IPC and reloads only what changed. Its behavior is identical whether HA is enabled or not.
What Does Not Change
The behavioral contract is preserved. Two-node active-active HA, the same replicated collections, the same operational model. The upgrade path from the current implementation will be clear and documented.
We will publish more detail, including the migration procedure for existing clusters, closer to the release date. If your deployment has specific edge cases you want to make sure we have covered, or if you’re interested in BETA-TESTING this new HA approach, please reach out to us directly via https://syngo.to/support.