
We put our new HA cluster through hell...
Spoiler alert: it didn't flinch :)

At Syncplify, we don’t test our software the easy way.
Meet grinder, our in-house multi-protocol stress testing utility. It doesn’t just push data at a server as fast as the network allows. It simulates the worst real-world conditions imaginable: connection drops, jitter, backoff cycles, the full chaos of a production environment having a very bad day. Two instances, each hammering a different node of the same cluster simultaneously, with 10 concurrent connections each and a 50MB buffer per session.
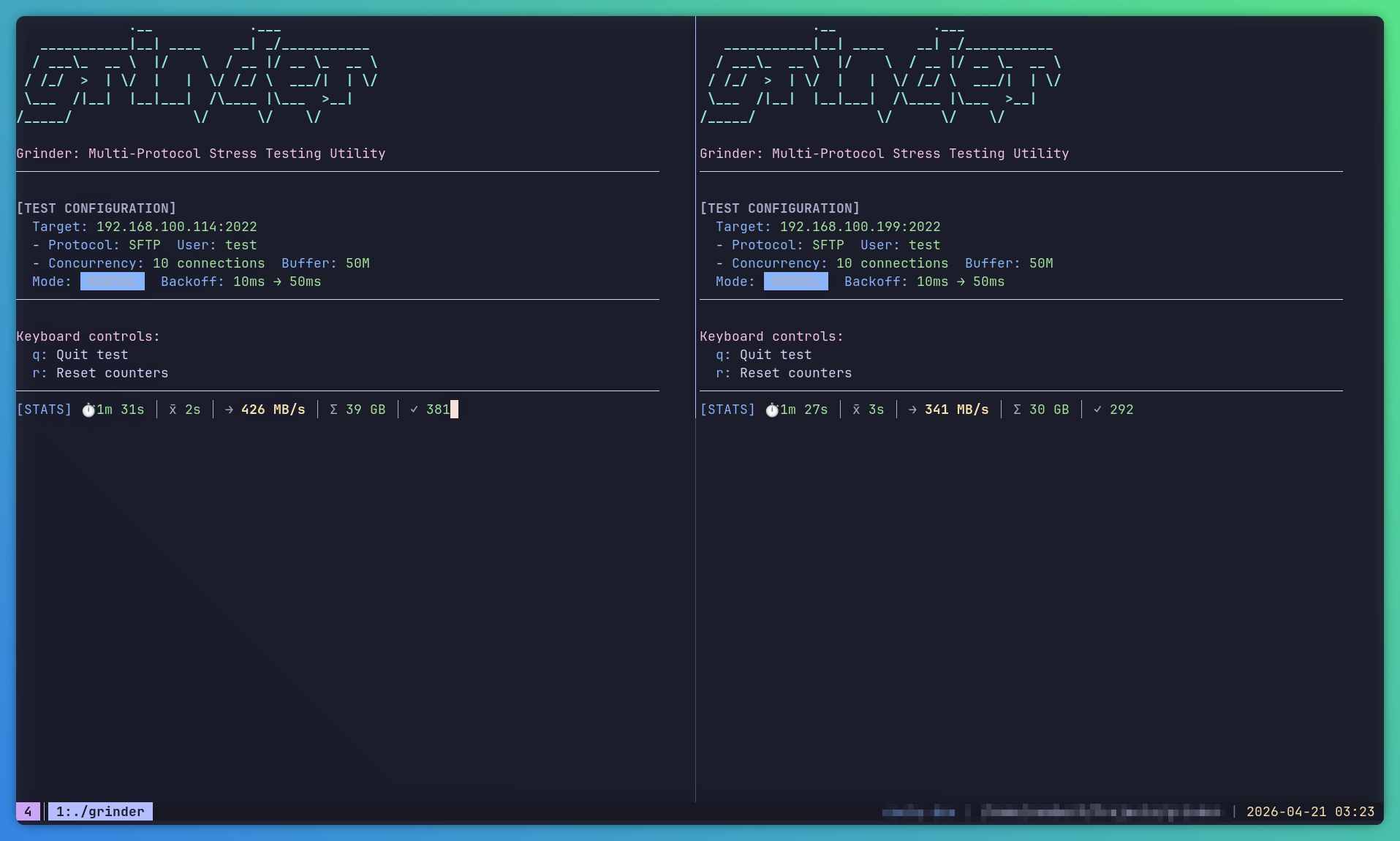
grinder instances in action simultaneouslyIn short: grinder is every SFTP server’s nightmare. And we pointed two of them at a two-node Syncplify Server! v7.5.0 HA cluster running our brand-new clustering subsystem.
The result? Completely smooth. Rock stable. Not a single crack.
Node one held at 426 MiB/s. Node two at 341 MiB/s. Combined throughput north of 750 MiB/s (that’s mebibytes per second, not megabits!) sustained across both nodes simultaneously, under full grinder conditions, while the HA subsystem handled synchronization in the background without breaking a sweat.
The dashboard tells the story clearly: 30-40 concurrent active sessions across both nodes, uploads and downloads running in parallel, data transfer peaking near 1,000 MiB/s on individual bursts. Zero rejected sessions. Zero instability.
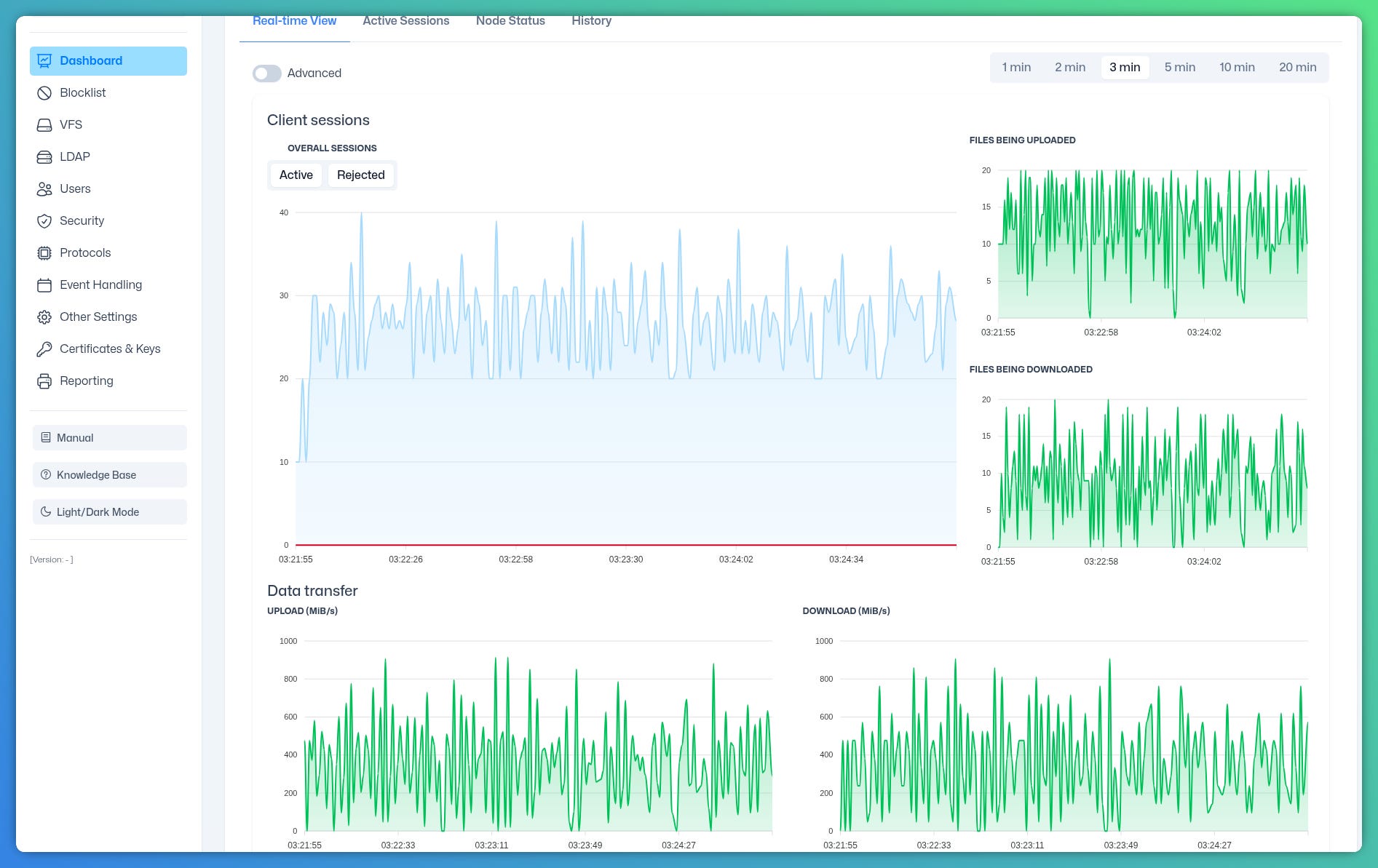
This is the same new HA algorithm we teased recently, the one we rebuilt from scratch to handle time drift, fast catch-up after node inactivity, and per-node per-site draining with full observability. Under grinder load, it performed exactly as designed.
We’ll have more to share soon, including the full release details. But if you run Syncplify Server! in a high-availability deployment you’ll definitely want to deploy this new version when it becomes available.